このトピックでは、Pegaでの文字列処理の方法を取り上げて説明します。
型
文字列型(Pega type: Text)は、Pega内部でJavaのString型を使用し表現されます。
チェック処理
Pega標準で用意された関数を一部抜粋します。
- @isDouble(inputString)
文字列が有効な倍精度数を表しているかどうかをチェックします。 - @isInteger(inputString)
文字列が有効な整数を表しているかどうかをチェックします。 - @isLiteral(inputString)
入力がリテラルかプロパティ参照かをチェックします。
検索処理
Pega標準で用意された関数を一部抜粋します。
- @indexOf(strStringToSearch,strStringToSearchFor)
strStringToSearchForにstrStringToSearchが最初に現れたインデックスを返します。値が見つからない場合は -1 を返します。 - @substring(stringToUse,startIndex,endIndex)
文字列のインデックスは0から数えられます。
変換処理
Pega標準で用意された関数を一部抜粋します。
- @toDate(inputString)
文字列を日付型に変換します。 - @toDateTime(inputString)
文字列を日時型に変換します。 - @toDecimal(inputString)
文字列を数値型に変換します。 - @toInt(inputString)
文字列を整数型に変換します。 - @toLowerCase(inputString)
文字列をすべt小文字に変換します。 - @toUpperCase(inputString)
文字列をすべて大文字に変換します。
編集処理
Pega標準で用意された関数を一部抜粋します。
- @replaceAll(aBaseString,aOriginalChars,aNewChars)
文字列aBaseStringのサブ文字列aOriginalCharsをaNewCharsに置き換えて返します。 - @trim(str)
strの頭と後ろのスペースを削除して返します。
補足
テキスト関連のPega標準関数はおもに「String」というライブラリで纏めて公開されているため、Designer StudioのRecordsブラウザで確認できます。

このトピックでは、Pegaにおける日付の処理方法を纏めて説明します。

型
Pegaでは内部的にBigDecimal(com.ibm.icu.math.BigDecimal)型を使用して、日付の値(1970/01/01からの日数)を保持しています。
なお、YYYYMMDD形式の文字列として日付型プロパティの値を読み書きできます。
但し、から文字列を設定する場合、プロパティの値が自動的に1970101に設定されるため、「空白」の表示にするには、設定処理自体をしないようにしましょう。
計算処理
(日付の加減算を行う)
指定された日付より何日前又は、何日後の日付を計算するには、addDays()関数を使用します。
- 構文
@(Pega-RULES: BusinessCalendar).addDays(startDate, daysToAdd, useBusinessCalendar, calendarName) - 例
例1: @(Pega-RULES: BusinessCalendar).addDays("20190808",30,false,Default) ⇒ 20190907
例2: @(Pega-RULES: BusinessCalendar).addDays("20190808",-9,false,Default) ⇒ 20190730
(日数を求める)
二つの日付の間の日数を計算するには、differenceBetweenDays()関数を使用します。
- 構文
@differenceBetweenDays(firstDate, secondDate, useBusinessCalendar, calendarName) - 例
@differenceBetweenDays("20190808","20190701",false,DEFAULT) ⇒ 38
(月の末日を取得する)
Calendar cal = Calendar.getInstance(); DateTimeUtils dtu = ThreadContainer.get().getDateTimeUtils(); //get info of date in parameter cal.setTime(dtu.parseDateTimeString(theDate)); calc.set(Calendar.DATE, c.getActualMaximum(Calendar.DATE)); Date lastDate = c.getTime(); return dtu.formatDateTime(dtu.formatDateTimeStamp(lastDate),"yyyyMMdd",null,null);
チェック処理
(営業日かどうかをチェック)
営業日かどうかをチェックするには、isBusinessDay()関数を使用します。
- 構文
@isBusinessDay(theDate, calendarName) - 例
例1: @isBusinessDay("20190803",DEFAULT) ⇒ true // 土曜日、法定休日でないため、営業日扱い
例2: @isBusinessDay("20190804",DEFAULT) ⇒ false // 日曜日
JavaVMとは
JavaVM(Java仮想マシン、Java Vitrual Machine、JVM)とは、Javaプログラムを実行するためのソフトウェアのことです。
JavaVMはWindowsやUnix、linux、MacOSなどのOSの上に動作するものですので、環境OS毎にそれぞれ異なる実装が作成されます。
それによって、Javaプログラムは「Write once, run anywhere」(WORA、一度書けば、どこでも実行できる)という特徴があり、特にプラットフォームに依存しません。
以下の図でそれらの階層関係を示します。

JREとJDK
JRE(Java Runtime Environment)とは、Javaプログラムの実行環境です。JavaVMとJavaプログラム実行に必要なライブラリが含まれています。
JDK(Java Development Kit)とは、Javaプログラムの開発環境です。JDKにはJREとJavaプログラムの開発に必要なツールなどが含まれています。
クラス
Javaプログラムの基本構成単位はクラスです。
コンパイルでネイティブ・コードを作成する C や C++ などの言語は、通常、ソース・コードをコンパイルした後、リンクを行う必要があります。このリンク処理では、ソース・ファイルを別々にコンパイルして得られたコードおよび共有のライブラリー・コードをマージして、1個の実行プログラムが作成されます。
クラスのリンクは、別個の手順としてではなく、JVM がクラスをメモリーにロードする際の処理の一部として行われます
Pegaでの基本の基本のコンセプトとしては、ルールとクラスがあります。
ルール
Pegaでは、公式的に「ルール」を以下のように定義しています。
A rule is a named business object that defines the behavior of part of an application。 ルールは、アプリケーションの一部の動作を定義する名前付きビジネスオブジェクトです。
すこし分かりにくいかもしれませんが、言い換えてみると、Pegaでのルールは、UIやデータモデル、ロジックなどPegaアプリケーションを構成する各々の部品です。
Javaなどのオブジェクト指向言語を使って開発されるアプリケーションのクラスや、SAP開発でのリポジトリオブジェクト(開発オブジェクト)に相当するものです。
Pegaは、ノンコーディング開発を謳っているため、コーディング上の用語を使用せずに、アプリケーションの各部品はそれぞれアプリケーションの一部の規則を定めているということから、「ルール」という名前を付けたでしょう。
ルールタイプ
ルールタイプはルールが所属しているタイプを定めております。Pegaでは多数のルールタイプが提供されており、その中に最も典型のは、画面のブロックを表すセクションや、ビジネスケースを表すケースタイプがあります。
ルールセット
ルールの開発とリリースを管理するには、ルールセットと呼ばれるグループにルールをまとめます。
ルールセットは名前(例:Pega-LP-ProcessAndRules:)とバージョン(例:07-10-01)で識別されます、ルールセットの内容を更新するには、新しいルールセットのバージョンを作成します。
レコード
アプリケーションを構成する各ルールは、それぞれのルールタイプのインスタンスとして作成されます。このルールタイプのインスタントはPegaでレコードとよばれます。
レコードは①ID、②ルールタイプ、③適用先のクラス(後続で説明)、④ルールセットの四つにより、Pegaシステム内にユニークで識別されます。
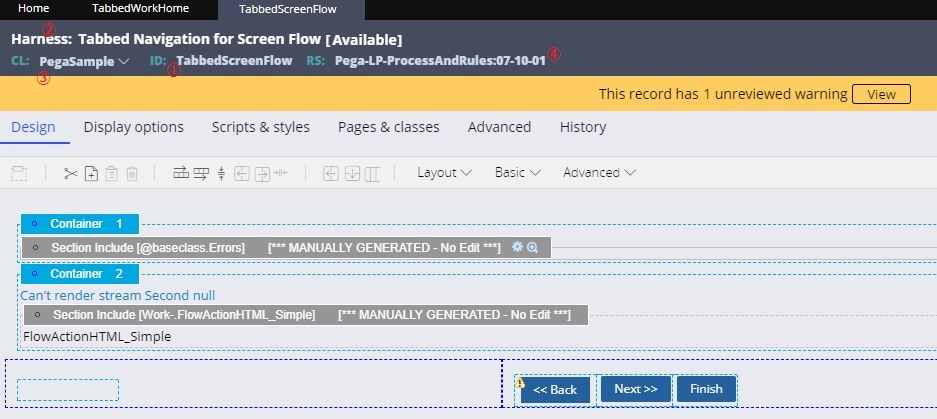
クラス
Pegaでは、公式的に「クラス」を以下のように定義しています。
A class groups a collection of rules or other objects. Each class defines capabilities (rules that include properties, activities, and HTML forms) that are available to other, subordinate classes, or to instances of the class。 クラスは、ルールまたは他のオブジェクトの集まりをグループ化したものです。各クラスは、他の下位クラス、 またはそのクラスのインスタンスで使用可能な機能(プロパティ、アクティビティ、およびHTMLフォームを 含むルール)を定義します。
(クラスの分類)
クラスは大きく下記の二つに分類することができます。
- concrete class
具象クラス。 - abstract class
抽象クラス
具象クラスは、インスタンスをデータベースに格納できます。対照的に、抽象クラスは通常、インスタンスを持たない、持つにしてもデータベースへの格納がなく、メモリ上の保持のみになります。
(クラスの階層)
Pegaではクラスに他のクラスを含めることもできます。
別のクラスを含むクラスは、親クラスと呼ばれ、別のクラスに含まれるクラスは、子クラスと呼ばれます。この親子関係によってPegaアプリケーションを構成する各クラスは一つのツリー構造で管理することができます。
各クラスの名前には、頭に親クラスの名前と区切り文字のハイフン(-)をふくめていますので、名前からクラス階層内でのクラスの位置を識別することができます。
(クラスの継承)
Pegaでクラスの間にルールを継承するには、パターン継承とダイレクト継承という2つの方法があります。
- パターン継承
パターン継承はクラス階層に則った親クラス(ビジネス上の関係を持ち、同じアプリケーションのクラスが多い)のルールをアクセスや上書きできます。 - ダイレクト継承
ダイレクト継承は、ダイレクトとして指定された親クラス(機能上の関係を持ち、別アプリケーションのクラスが多い)のルールをアクセスや上書きできます。

継承を通じてルールを再利用しようとすると、Pegaでは最初にパターン継承で(デフォルト、クラスの定義画面で変更可能)指定される親クラスから検索されます。その検索で見つからない場合に、ダイレクト継承で指定される親クラスが新たなパターン継承検索のベースとなって検索されます。このプロセスは、クラス階層の最後のクラスが検索されるまで繰り返されます。この最後のクラスを、最終ベースクラス、または@baseclassと呼びます。@baseclassを検索してもルールが見つからないと、ペガからエラーが返されます。

ソフトウェア工学が扱う対象の基本的な構成要素は,プロダクト (product) とプロセス (process) です。
プロダク トとはエンジニアリングの過程で生成される中間製品や文書を含めたすべての生産物を指し、プロセスはプロダ クトを生み出す工程です。
これらの作業をスムーズに行えるようにするための各種の方法・手順・手段を纏めて、なんらかの原理や観点に基づいて統合した知的体系として定義されるのは、ソフトウェア開発方法論のことです。
開発技法
ソフトウェア開発技法は、ソフトウェアを開発する技術方法やテクニックのことです。
以下の表でソフトウェア開発の局面別の技法を示します。
| 局面 | 技法 |
|---|---|
| 要求 | 要求定義技法 |
| 分析 | 分析技法 |
| 設計 | ソフトウェア設計技法 |
| 実装 | プログラミング技法 |
| 検証 | ソフトウェア検証技法 |
プロセスモデル
ソフトウェア開発プロセスは、ソフトウェアをどのように作り上げるかについて,手順や工程、成果物、進め方に関する基本的な考え方を定義したものです。ウォーターフォール型、反複型などが挙げられます。
ソフトウェア開発プロセスは、ソフトウェア開発モデルと呼ばれることもあります。
コンポーネントベース開発(Component-Based Development,CBD)とは、ソフトウェアを機能又はその他何かの単位で部品に分割し、得られたソフトウェア部品を組み合わせることによって開発を進めるソフトウェア開発方法です。
クラスライブラリやフレームワークに代表されるオブジェクト指向(OOA)が効果的な再利用を実現できなかったことから、 それらの研究を継承・発展させる形で登場してきたコンポーネント指向ソフトウェア開発は、以下のような効果をもたらすと期待されています。
- 開発効率性
既存のコンポーネントを再利用することで、 目的とするソフトウェアの開発期間を短縮し、 開発コストを削減することができます。 - 適応性
構成する個々のコンポーネントの置換・修正作業によって、ソフトウェア全体の要求仕様や運用環境の変化に対応することができます。 - 信頼性
信頼性の高いコンポーネントを組み合わせることで、 ソフトウェア全体について一定以上の信頼性が得られます。 - 位置透過性
インタフェースと実装の分離に基づき、コンポーネントを分散オブジェクトとすることで、 ネットワーク上におけるコンポーネント群の配備状況を意識する必要が減少されます。
本トピックは、まずコンポーネントの定義を明確にして、それからコンポーネント指向開発の説明を展開します。
コンポーネントとは
コンポーネントというのは、部品、成分、構成要素などの意味をもつ英単語(Component)です。その意味で様々な分野で使われていますので、ITの分野では、システム・コンポーネントや、ハードウェア・コンポーネント、ソフトウェア・コンポーネン、ネットワーク・コンポーネントトといった場面があります。 ほかに意味の似た単語に「モジュール」(module)がありますが、違いとしては、「モジュールには、他の部品への接合部の仕様が標準化され、容易に追加や交換ができるような構成要素といった意味合いが込められることが多いのに対し、コンポーネントは単純に要素や部品一般のことを指すことが多い」とされています。。
ソフトウェア分野のコンポーネントとは、ある機能を実現するために部品化されたソフトウェア又はその構成要素のことで、ソフトウェア・コンポーネント(Software Component)の略です。
ソフトウェア分野で「モジュール」もよく使われますが、両者の違いとしては以下の見解が一般的です。
- コンポーネント:それだけで完結した部品
- モジュール:粒度が少し高い部品を構成するための内部要素
規模の大きさではなく枠組みとしては「コンポーネント>モジュール」の感じです。
コンポーネントの見方
コンポーネントには、実装部品とサービス部品の二つの見方があります、 前者は、GUI部品やEJBなどのプログラムに組み合わせて使うものを指し、後者は、業務機能やWebサービスなど必ずしも実装の実体とは限らないロジックプロセスの処理単位を指します。 下記の表にて各視点からふたつの見方の違いを説明します。
| 視点1:配置/ランタイム | 視点2:静的に/動的に | 視点3:物理/論理 | |
|---|---|---|---|
| 実装部品 | 配置モデルのシステム構成要素 | 静的なアーキテクチャモデルのシステム構成要素 | 物理構成要素 |
| サービス部品 | ランタイムモデルのシステム構成要素 | 動的なアーキテクチャモデルのシステム構成要素 | 論理構成要素 |
コンポーネントの技術
コンポーネントの実装技術はいかのようなものがあげられます、カッコ内にあるのはそのコンポーネント技術を開発した会社又は組織の名称です。
- OSGI组件模型
- J2EE组件模型(Sun Microsystems社、現在はOracle社)
- COM组件模型(Microsoft社)
- NWDI组件模型(SAP社)
- VCL(CLX)组件模型(Borland社、現在はMicro Focus社)