概要
データ指向アプローチ(Data Oriented Approach)とは、業務で扱うデータの構造や流れに着目し、システム設計を行う手法であり、企業で扱うデータの統一的なデータベースを作り、一元化することで個々のシステム設計をシンプルにするというアプローチです。
モデリング手法
DOAでは、まず業務で扱うデータ全体をERモデル(Entity-Relationship model)によってモデル化し、それを正規化してRDB(リレーショナルデータベース)を設計します。
個々のシステムはこのデータベースを中心に設計されます。
利点
DOAは、統一的なデータベースを中心にして各部署のシステムが設計されるため、データの整合性・一貫性が保たれ、システム間のやりとりが容易になります。
また、業務内容の変更によりシステム改変が必要になった時も、データベースの構成が定まっているため、POAよりも改変が容易になります。
欠点
DOAは、データとプログラムが切り離されているため、一度モデリングしたデータ構造を変更すると,関連するプログラムを特定するのが極めて難しいことです。
このため,システムの追加・修正の際にデータ構造を変更する必要があると,多大な手間と時間が掛かります。
概要
プロセス指向アプローチ(Process Oriented Approach,POA)は、データの「入力」、「加工」、「出力」という3つのまとまりから成る「処理」に重点を置いたアプローチです。
ただし、データを完全に無視しているわけではなく、POAでは、システムを構成する処理と処理の間をデータが通過していくと考え、データを処理の附属的な存在と捉えています。
モデリング手法
POAの代表的な表記法であるDFDは、構造化分析で有名なトム・デマルコ氏が提唱した表記法です。
DFDは「データの流れ図」という意味だが、実際にはシステムを構成する「処理」の構造に着目しています。
例えば、販売管理システムのDFDは、下記の図のように記述できます。

「顧客」というデータの発生源(源泉と呼ぶ)から生じた「注文」データが、「受注」→「在庫チェック」→「出荷」→「請求」という処理をたどって加工されながら流れていきます。
「受注」と「在庫チェック」という処理を実施するために、「顧客マスタ」と「商品マスタ」というファイル(データ)が参照されます。
ただしPOAでは、あくまでシステムの主役が「処理」であるため、これらのデータが一元管理されているわけではなく、システムごとに用意する必要があります。
利点
POAは、業務の手順や工程を図などに書き表して定義し、それに合わせてソフトウェアやシステムの挙動を決定していく。現実の手順に基いてシステムの動作を考えるため分かりやすく、設計工程を比較的容易に素早く進めることができます。
欠点
POAは、業務内容を中心に設計されるため、各部署の業務内容に応じて独立したシステムになることが多く、システム間のやりとりが複雑になるという問題点がありました
また、システムが業務内容に強く依存しているため、業務内容が変更になった時には、システムの大幅な改変が必要です。
ウォータフォールモデルは、古くから利用されているシステム開発モデルで、ほとんどの開発プロジェクトでこのモデルが使用されるほど広く普及していました。
このモデルは、ソフトウェアの各開発工程を上流から下流まで段階的に区切りながら、流れ落ちる滝のように見立てています。
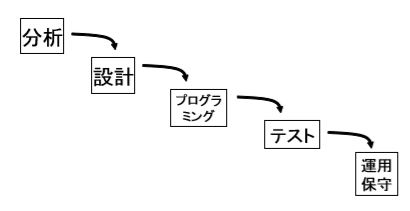
特徴
ウォータフォールモデルは、原則的に手前の工程に遡ることができないので、以下のような特徴をもっております。
- 開発工程を明確に区切って、各工程毎に厳密な確認と検証を行う
- 各工程の成果物を文書にきちんと纏めて、そのアウトプットを次の工程のインプットにする
利点
ウォータフォールモデルの利点は、管理と工数見積もりがやりやすいところです。
- 開発管理がやりやすく、特に大規模なソフトウェア開発に適している
- 工数見積もりがやりやすい、特に人月ベースの契約受注プロジェクトに適している
- 業務コンサルタント、システムエンジニア、プログラマ、テスタによる分業体制が確立しているため、 参加者が担う役割は固定的で考える事が少ない
- 要員の調達が比較的に容易に行えるため、特に労働集約型ビジネスモデルに適している
欠点
ウォータフォールモデルの欠点は、コストが高く品質管理がしにくいところです。
- ソフトウェアの実物を見られるようになるまでの時間が長い
- 設計と設計の成果物の検証とも机上レベルでしかできず、品質が担保しにくい
- 問題の早期発見が難しく、遅れるほど解決のコストが大きくなる
- 価値が少ないドキュメント作成にもやたら工数がかかる
このためウォータフォールモデルを採用するほとんどの開発プロジェクトでは、前工程の完了要件(要件定義局面であれば、要件定義書などの成果物の完成)を徹底して品質を高め、後戻りの発生率を可能な限り低下させるとともに、後戻りが発生する場合は変更管理によって公式に決定し、後戻りや横展開を確実にフォローするように工夫しております。
モデリングするには、モデリング言語を使用します。
モデリング言語は、ルールの一貫したセットで定義された構造によって情報、知識あるいはシステムを表現するため使われるあらゆる人工言語のことです。
モデリング言語は図式またはテキスト形式であり得ます。
- 図式モデリング言語
図式モデリング言語は、概念を表す名前を持つシンボルと、そのシンボルを結合しその関係を表現するライン、及び制約を表現する様々な図式表記を持つダイアグラム技術を使います。 - テキスト形式モデリング言語
テキスト形式モデリング言語は通常、コンピュータが解釈可能な表現にするパラメータによって達成される標準化されたキーワードを使います。
モデリングを行う手法としては、分類や分割、階層化といった方法があります。これも人間が世界を認識するための基本手法です。
- 分類
分類とは、事物や現象を、何らかの基準に従って区分することによって体系づけることです。
例えばある企業の人事システムでは、従業員を職位に従って、一般社員、係長、課長、部長、社長に分類することがあります。 - 分割
分割とは、複雑なものをより簡単な構成要素に分けることです。
システムを複数のサブシステムに分けたり、業務を複数の機能に分けたりします。 - 階層化
階層化とは、システムを互いに独立している複数の階層に分けて分析、設計及び実装のことです。
モデリングとは、業務の流れやシステムの構成、といった、論理世界にしか存在しないものを可視化するための技法です。
モデリングは、記号を使ってモデルを作成することによって、問題点の洗い出しや理解の深まり、人間同士間の認識共有を図ります。
なお、業務やシステムを視点に分けてモデリングすることによって、複雑なものを単純化にして人間に理解しやすくすることができます。
人間同士の認識共有
ソフトウェアシステム開発に関わる人間は主に、ソフトウェアシステムを利用する「ユーザ」とソフトウェアを開発する「エンジニア」に大別することができますので、人間同士間の認識共有も、ユーザとエンジニア間の認識共有とエンジニア同士間の共有に分けることができます。
- ユーザとエンジニア間の認識共有
ソフトウェア開発では、ビジネスによる要件とシステムによる実装の間には大きな溝があります。エンジニアが直接自分が欲しいと思うソフトウェアを書く場合は、そのようなことはないかもしれません。
しかし、ソフトウェアのことを知らないユーザからの依頼によってソフトウェアの開発を行う場合には、当然この溝は非常に大きなものになります。
この溝を埋めるために用いる技術が「モデル」です。モデルを仲介して要件と実装の間の溝を埋めます。 - エンジニア同士間の認識共有
ごく小さいソフトウェアは一人で作り上げることもあるかもしれませんが、殆どの場合はチーム合同の作業になります、なかでは何百人、何千人のエンジニアが同時に開発を行うプロジェクトも少なくありません。
そこで分析や設計、実装、テストなどの作業を別々の人に担当してもらうのは殆どですので、モデルを通じて、エンジニア同士間の認識共有を図ります。
複雑なものを単純化
業務やシステムは複雑で,そのまま理解することは通常、人間にとっては難しいものです。
着目する視点を分けてモデリングすることによって、業務やシステムを単純化し,理解しやすくします。ただし,業務やシステム自体が単純になったわけではなく,単に着目する部分を絞っているだけです。
モデルは、図や表等でものごとを単純化して表現したものであり、以下のように様々な視点から分類することができます。
- 言語・表記法
- 対象
- 領域・局面
- 静的か動的か
- 論理か物理か
本トピックでは、各視点からのモデルの分類をそれぞれ説明します。
言語・表記法による分類
モデリング技法は、その仕様や成果物を言語・表記法としてまとめて公開されます。 以下によく使用されているモデリング言語・表記法を取り上げます。
| No. | 言語 | 説明 | SubNo. | 表記法 | 説明 |
|---|---|---|---|---|---|
| 1 | UML | Unified Modeling Language 統一モデリング言語 | - | - | - |
| 2 | BPMN | Business Process Modeling Notation ビジネスプロセスモデリング表記法 | - | - | - |
| 3 | ERD | Entity-Relationship Diagram 実体関連図 | 1 | IDEF1X | - |
| 2 | IE表記 | - | |||
| 4 | DFD | Data Flow Diagram データフロー図 | 1 | Yourdon&Coad記法 | - |
| 2 | Gane&Sarson記法 | シンボルは4つのみ | |||
| 5 | FlowChart | 流れ図 | - | JIS. X. 0128. -1988 | - |
モデリング技法は、基本的に形式化されたシステム言語を使用してモデルを記述しますが、UMLのユースケースのように自然言語で記述されるモデルもあります。
対象による分類
モデリング対象によって、モデルを以下のように分類することができます。
| No. | 対象 | UML2.0 | BPMN | ERD | DFD | 流れ図 |
|---|---|---|---|---|---|---|
| 1 | ビジネス | アクティビティ図
ユースケース図 コミュニケーション図 クラス図 オブジェクト図 | ○ | ○ | ○ | ○ |
| 2 | 組織 | クラス図
配置図 | × | ○ | × | × |
| 3 | データ | クラス図
オブジェクト図 パッケージ図 | × | ○ | × | × |
| 4 | システム | コンポーネント図
パッケージ図 クラス図 オブジェクト図 配置図 アクティビティ図 シーケンス図 コミュニケーション図 | × | ○ | ○ | ○ |
| 5 | プログラム | クラス図
コンポジット構造図 オブジェクト図 パッケージ図 アクティビティ図 ステートマシン図 シーケンス図 コミュニケーション図 | × | ○ | ○ | ○ |
領域・局面による分類
モデルの種類としては、「問題領域(problem domain)」モデルと「解決領域(solution domain)」モデルの二つに大別することができます。
- 問題領域モデル
「何(what)」をするのかをモデル化したものです。 - 解決領域モデル
その「何」をどう実現するのかをモデルしたものです
問題領域モデルと解決領域モデルは、目的に応じてさらに細分化されます。
| 領域 | モデル |
|---|---|
| 問題領域 | ドメイン分析モデル |
| 要求分析モデル | |
| 解決領域 | システム分析モデル |
| 設計モデル | |
| 実装モデル |
- ドメイン分析モデル
現実世界をモデリングしたモデルです。 - 要求分析モデル
やりたいことをモデリングしたモデルです。 - システム分析モデル
プログラミング言語や実行環境といった実現方法に依存しない、ITシステムとして本質的なレベルでの解決方法をモデリングしたモデルです。 - 設計モデル
プログラミング言語や実行環境を前提に具体的な実現方法をモデリングしたモデルです。 - 実装モデル
プログラミング言語などによる実装を指します。
静的か動的かによる分類
モデルを静的モデルと動的モデルに分類することができます。
- 静的モデル
静的な構造に関するモデルです。 - 動的モデル
動的挙動に関するモデルです。
| No. | 区分 | UML2.0 | BPMN | ERD | DFD | 流れ図 |
|---|---|---|---|---|---|---|
| 1 | 静的モデル | クラス図
コンポジット構造図 コンポーネント図 配置図 オブジェクト図 パッケージ図 | × | ○ | × | × |
| 2 | 動的モデル | アクティビティ図
ユースケース図 ステートマシン図 相互作用概要図 シーケンス図 コミュニケーション図 タイミング図 | ○ | × | ○ | ○ |
論理か物理かによる分類
モデルを論理モデルと物理モデルに分類することができます。
- 論理モデル
概念上のモデルやプログラム内に存在するオブジェクトに対するモデルです。 - 物理モデル
ファイルやノードなど具体的に扱うことができるリソースに対するモデルです。
| No. | 区分 | UML2.0 | BPMN | ERD | DFD | 流れ図 |
|---|---|---|---|---|---|---|
| 1 | 論理モデル | クラス図
コンポジット構造図 コンポーネント図 オブジェクト図 パッケージ図 その他振る舞いを表現する図 | ○ | ○ | ○ | ○ |
| 2 | 物理モデル | コンポーネント図
配置図 その他振る舞いを表現する図 | ○ | ○ | ○ | ○ |
コンピュータを構成する回路や装置などの物理的実体をハードウェア(Hardware)と呼ぶのに対し、ソフトウェア(Software)とは、そのハードウェアの上で動作して何らかの処理を行うプログラムのことです。
ソフトウェアにはさまざまな分類方法があります。
レイヤから分類
- 基本ソフトウェア
ハードウェアの基本的な制御を行い、ハードウェアの資源を有効活用するとともに、多くのソフトウェアが共通して利用する基本的な機能などを実装して、システム全体を管理するソフトウェアです。
主にOSのことを指しており、例えば、Windows、Unix、Linux、Android、iOSなどがあります。 - ミドルウェア
基本ソフトウェアと応用ソフトウェアの中間に位置し、OSの上に動作して応用ソフトウェアに対してOSよりも高度で具体的な機能を提供します。
データベース管理システム(Oracle、SQLServer…)、アプリケーションサーバ(Websphere、Webogic…)などがあります。 - 応用ソフトウェア
ユーザの利用目的に応じて作られたソフトウェアであり、アプリケーションソフトウェアとも呼ばれます。
Officeや会計ソフト、グループウエアなどがあります。
役割にようる分類
- 基盤ソフトウェア
企業などのソフトウェアシステムをサポートするために必要な共通機能を提供するものです。
例えば、OS、データベース、メールサーバ、ネットワーク管理、セキュリティ管理などがあります。 - ユーティリティーソフトウェア
コンピュータ上で機能する、補助的な機能を提供するソフトウェアであり、ツールソフトウェアや単にユーティリティーとも呼ばれます。
ファイルエディタや圧縮ツール、画像編集ツールなどがあります。 - 情報処理ソフトウェア
情報システムを構成するソフトウェアです。 - 組込ソフトウェア
産業機器や家電製品などに内蔵され、特定の機能を実現するための組み込みシステムで動作するソフトウェアです。 - ゲームソフトウェア
コンピュータゲームのソフトウェアのことです。 - …
ビジネス形態による分類
- 市販ソフトウェア
ソフトウェア開発に携わっている企業および会社が有料で販売しているソフトウェアです。一般販売しているため、OSやOfficeといった、広く利用できる汎用的なものが多い。
販売形態については、昔から主流だったパッケージ販売(量販店などの店頭で、記憶メディアに記録され、包装されたパッケージの状態で販売する)や、インターネットが普及してからのダウンロード販売、SaaS・クラウドが発展してからのサービス販売などがあります。 - 自社開発ソフトウェア
自社が使用するソフトウェアを自社で開発することです。 - オーダー生産ソフトウェア
自社が使用するソフトウェアの開発をベンダに委託することです。 - フリーソフトウェア
無料で提供されるソフトウェアであり、オンラインで配布されることが多い。 - シェアソフトウェア
無料な試用期間を設けて、試用期間後でも継続的な使用する場合は有償になるソフトウェアであり、フリーソフトウェアと同じ、オンラインで配布されることが多い
工学(Engineering)とは、主に数学、化学、物理をベースとする自然科学などの知識を応用して、実用的な技術発見や製品開発などを研究対象とする学問の総称です。
工学と対照的には、理学(Science)、医学(Medicine)、農学(Agriculture)などの分類があります。
工学の分類
工学には様々な分類がありますが、以下はその代表的な一部です。
- 建築工学
- 機械工学
- システム工学
- 情報工学
- 電子工学
- 鉄道工学
- コンピュータ工学
工学の共通点
工学の共通点としては、以下のような作業を共有していることです。
- モデリング
なにが問題で,どんなものを作るべきかを明確にするため、対象領域を分析して,モデル化する技術が重要です - 仕様
工学はきちんとした仕様を明確しなければなりません - 成果物
工学はなんらかの成果物を作成しています - 設計
工学の核は設計技術です。 - 検証
成果物が仕様に満たしているかどうかを検証しなければなりません
ソフトウェア工学
ソフトウェア工学(Software Engineering)とは、ソフトウェア開発を研究対象とする工学で、ソフトウェアを効率的に設計、開発するための手法に関する学問、もしくはそのための技術のことをいいます。
情報システムとは
ソフトウェア業界の仕事は、情報システム開発が大半を占めているため、ここで情報システムのことを特別に取り上げて説明します。
情報システム(Information System)とは、情報を適切に保存・管理・流通するための仕組みやシステムのことです。言葉の意味からすれば、コンピュータを使わなければならないことはないですが、現代ではほとんどの場合、情報システムは「コンピュータ情報システム」の略として用いられています。
情報システムは、ハードウェア、ネットワーク、ソフトウェアを組み合わせて構成されたシステムであるため、ソフトウェアを含めているイメージですが、情報システム構築時は、構成要素のハードウェアは調達するものであり、開発する必要なのはソフトウェア部分のみですので、情報システムの開発=情報システムにおけるソフトウェアシステム開発として、ソフトウェア工学の最も重要な一大分野になっております。
ソフトウェアのライフサイクル
全てのソフトウェアにはライフサイクルがあります。
ほとんどの場合、ソフトウェアは、「企画」→「開発」→「運用」→「廃棄」からなるライフサイクルをたどると考えれ、ソフトウェア工学の研究対象は主にそのなかの「開発」になります。 ソフトウェアにはリニュアルやバージョンアップがよくあるものですが、ライフサイクルからみれば、新旧バージョンを別々のソフトウェアととらえることができます。
ソフトウェアの品質
ソフトウェアの品質特性は大きく6つに分類され、それぞれの英語の頭文字をとってFRUEMP特性とも呼ばれています。- 機能性
必要な機能を満たしているかということです。 - 信頼性
指定された条件の下で正しく動くかということです。 - 使用性
使いやすさを表します。 - 効率性
スピードとサイズに関する性能です。 - 保守性
修正のしやすさです。 - 移植性
実行する環境の移行のしやすさを表します。
プロジェクト管理
ソフトウェアプロジェクト管理 (Software Project Management) は、ソフトウェアプロジェクトを計画し導く技術です。
プロジェクト管理の一分野として、ソフトウェアを開発するための組織、チーム、個人のあり方、つまり人間の問題を取り扱うため、「もの」が取り扱う対象のソフトウェア工学の分野には分類されません。
スコープ(scope)とは日本語にすると“有効範囲”を表します。つまり、変数のスコープは変数が使える有効範囲のことを指します。
スコープの分類
スコープは、主に以下のように分類することができます。
- グローバル・スコープ (global scope)
- ファイル・スコープ (file scope)
- ローカル・スコープ (local scope)
- 静的なローカル・スコープ (static local scope)
- インスタンス・スコープ (instance scope)
- クラス・スコープ (class scope)
- クロージャ・スコープ (closurel scope)
- スレッドローカル・スコープ (threadlocal scope)
グローバル・スコープ
グローバル(global)は、日本語にすると”大域”を表し、グローバル・スコープ(global scope)は、プログラムの「全体」から見えるスコープのことです。このスコープに属する変数はグローバル変数といわれます。BASICのような単純な言語ではグローバル・スコープしか存在しない場合があります。Pythonのようなグローバル変数の書き換えが簡単には行えない言語も存在する。
ファイル・フスコープ
ファイル・フスコープ(file scope)は、グローバル・スコープと似ていますが、プログラムを記述したファイルの内側でのみ参照できるスコープです。プログラムが複数のファイルから構成される場合は他のファイルから参照することはできません。
ローカル・スコープ
ローカル(local)は、日本語にすると”大域”を表し、ローカル・スコープ(local scope)は、ある関数やブロックの範囲内に限定されたスコープのことです。
何を持って範囲を与えるかは言語により様々だが、一般に入れ子のローカル・スコープは外側を参照できるのが普通です。このとき兄弟関係にあるスコープは見えない。変数宣言が必要な言語の場合は宣言文以降にスコープが制限される場合が多い。
- 関数の先頭で纏めて宣言しなければならない
例:Pascal、Delphi - 関数のどこでも宣言でき、関数全体で有効
例:Javascript - 関数のどこでも宣言でき、宣言以降の関数全体で有効
例:ABAP - 関数のどこでも宣言でき、宣言のブロックの中にのみ有効
例:C、C++
インスタンス・スコープ
インスタンス・スコープ (instance scope)は、クラスベースのオブジェクト指向言語で、各インスタンス毎に割り当てられた変数が所属メソッド(メンバ関数)からのみ参照されるスコープのことです。いわゆるカプセル化はこれを指します。。保護されない変数の場合は、クラス定義が見えていてオブジェクトにアクセスできる場合は直接参照できます。C言語の構造体参照なども一種のインスタンススコープです。
クラス・スコープ
クラス・スコープ (class scope)は、 クラスベースのオブジェクトト指向言語で、あるクラスの定義全体から参照できるスコープのことです。インスタンス・スコープと異なり変数が共有されますので、ある種の制限されたグローバル・スコープと考えることができます。クラス・スコープをもたない言語の場合でも、ファイル・スコープを用いることで同様の機構を実現できる場合があります。
クロージャ・スコープ
クロージャ・スコープ (closurel scope)
スレッドローカル・スコープ
スレッドローカル・スコープ(threadlocal scope)は、同じスレッドしか参照できないスコープのことです。マルチスレッド・プログラミングではよく使われます。
各言語の実装
以下の表で各主流言語のスコープ実装状況を示します。
| 言語 | グローバル・スコープ | ファイル・スコープ | ローカル・スコープ | 静的なローカル・スコープ | インスタンス・スコープ | クラス・スコープ | クロージャ・スコープ | スレッドローカル・スコープ |
|---|---|---|---|---|---|---|---|---|
| ABAP | ○ | × | ○ | × | ○ | ○ | × | × |
| Basic | ○ | × | × | × | × | × | × | × |
| C | ○ | ○ | ○ | ○ | × | × | × | ○ |
| Cobal | ○ | × | × | × | × | × | × | × |
| C++ | ○ | ○ | ○ | ○ | ○ | ○ | × | ○ |
| C# | × | × | ○ | × | ○ | ○ | × | ○ |
| Delphi | ○ | × | ○ | × | ○ | ○ | × | ○ |
| Fortran | ○ | × | ○ | ○ | × | × | × | × |
| Java | × | × | ○ | × | ○ | ○ | × | ○ |
| JavaScript | ○ | × | ○ | × | × | × | × | × |
| Pascal | ○ | × | ○ | × | × | × | × | ○ |
| Perl | ○ | × | ○ | × | ○ | ○ | × | ○ |
| PHP | ○ | × | ○ | × | ○ | ○ | × | × |
| Python | ○ | × | ○ | × | ○ | ○ | ○ | ○ |
| Ruby | ○ | × | ○ | × | ○ | ○ | ○ | ○ |
| VB | ○ | × | × | × | × | × | × | × |
| VB.net | ○ | × | × | × | × | × | × | ○ |
| VC++ | ○ | × | × | × | × | × | × | ○ |
| VC++.net | ○ | × | × | × | × | × | × | ○ |
プログラミング言語で記述されるプログラムは、区切り文字で区切られた一連のトークンから構成されます。
トークンとは、基本的な構文要素としてプログラム内で意味を持つテキストの最小単位であり、字句ともいいます。
トークンを組み合わせて、式や宣言や文を組み立てます。 文とは、プログラム内で実行可能なアルゴリズム動作を記述するものです。
このトピックでは、汎用的な視点から、プログラミング言語を構成する要素を説明します。
プログラミング言語の構成要素には下記のものがあります。
- 字句構造
- データ型、値及び変数
- 式
- 文
- ブロック
- 構造化
- オブジェクト指向
- 例外処理
字句構造
字句構造(英:lexical structure)とは、プログラミング言語の字句解析が想定するトークンの構造のことです。 トークンには主に以下のような種類があります。
- リテラル(英:literal)
- 識別子(英:identifer)
- キーワード(英:keyword)
- 演算子(英:operator)
- 区切(英:punctuator)
- コメント(英:comment)
データ型、値及び変数
データ型(英:data type)とはデータの扱いに関する形式のことです。データ型は、プログラミングなどにおいて変数(英:variable)そのものや、その中に代入されるオブジェクトや値(英:value)が対象となります。データ型は単純型と複合型2種類に分類することができます。
- 単純型
単純型とはプログラミング言語の仕様に元から存在する型であり、組み込み型、原始型、プリミティブ型、基本型などと呼ばれることもあります。単純型は、数値型、文字列型、論理型、ポイント型などの種類があります。 - 複合型
複合型とは、プログラマがソースコードの記述などにより新たに作る型であり、複合データ型、ユーザ型、ユーザ定義型、参照型、リファレンス型などとも呼ばれることがあります。複合型は構造体、クラス、インタフェース、共用体、列挙型などの種類があります。 なお、プログラミング言語により、一部型がなかったり、単純型か複合型かの分類が違ったりすることがあります。
式
式(英:expression)とは、言語によって定められた優先順位や結びつきの規定に則って評価される値、変数、演算子、関数の組み合わせのものです。
数学における式と同様、式は評価された値を持っています。
文
文(英:statement)とは、一つ以上の式や関数呼び出しで作られる、手続き構造の分割できない基本単位のものです。
if文のように分岐構造を表すものや、代入文のように変数の値を変更するものなどがあります。
ブロック
ブロック(英:block)は複数の文から構成されます。ブロックには、単純な複数文が並べられた「順次構造」や、if-else-endifのような「選択構造」、for-nextのような「反復構造」があります。
プログラムの基本構造は、「順次構造」、「選択構造」、「反復構造」の3つからなると考えられます。 基本的にはプログラムは先頭行から順に実行されていきます(順次構造)が、実際にはその流れを条件によって分岐させたり(選択構造)、同じ箇所を繰り返し実行させたりすること(反復構造)を頻繁に行います。
構造化
殆どのプログラミンググ言語では、プログラム中で意味や内容がまとまっている作業をひとつの手続きとして定義できる仕組みが用意されていて、手続きの呼び出しによりプログラムが成り立ちます。
プログラミング言語により、手続きそのものは、サブルーチンやプロシージャ、関数、メソッドなどさまざまの呼び方が存在します。
オブジェクト指向
オブジェクト指向(英:object-oriented)とは、オブジェクト同士の相互作用としてシステムの振る舞いをとらえる考え方です。 構造化がデータとそれを処理する手続きを分離する考えに対して、オブジェクト指向はデータとそれを処理する手続きを纏めて、オブジェクトとして表現します。
オブジェクト指向は、JavasSriptのようなプロトタイプベースのものと、c++、javaなどのクラスベースのものがあります。 クラスベースで実現されるプログラミング言語では、クラスやインタフェースの作成、クラスの継承などの仕組みが提供されています。
例外処理
例外処理(英:exception)とは、プログラムがある処理を実行している途中で、なんらかの異常が発生した場合に、現在の処理を中断(中止)して、別の処理を行うことです。
例外処理がサポートされているプログラミング言語では、異常が発生可能な処理をtryブロックに入れて、例外が発生した時の処理をcatchブロックに入れるのが多く見られます。
以下の表にて言語の主な歴史を示します。
| キーワード | 年度 | 言語 | 開発者 | 特徴&言語歴史への影響 |
|---|---|---|---|---|
| 機械語・アセンブラ言語- | - | - | - | - |
| 高級言語 | 1957年 | FORTRAN | IBM社 | 高級言語としては最初のものである、現在も科学技術計算など大規模な計算を必要とする分野で使用されている |
| 1958年 | ALGOL58 | - | 構造化プログラミングの考え方を取り入れた最初の言語である、あまり普及しなかったが、後に登場するPascalやC言語など多くの言語に影響を与えた | |
| 1960年 | Cobol | J.Sammet | 初期の高級言語の1つであり、事務処理言語として広く普及した。現在でも企業の事務処理系システムで利用されている | |
| 1960年 | LISP | MIT | ボーランド記法を使用した独特の文法を持つ言語であり、「純粋ではない」が最古の関数型言語でもある。現在でも人工知能やEmacsのマクロなどに使用されている | |
| 1964年 | Basic | ダートマス大学 | その後、1970年代にマイクロソフトがMS BASICを発表し、8bitマシン時代 (1970年代後半-1980年代前半)の中心的な言語となった | |
| 構造化言語 | 1966年 | BCPL | ケンブリッジ大学 | 現在のコンパイラ技術の基礎を確立し、後にB言語に影響を与え、C言語へと発展した |
| 1967年 | Simula | ノルウェー計算センタ | オブジェクトの概念をもつ言語としては最古の言語である | |
| 1969年 | Pascal | - | 中期の代表的な構造化言語の1つ。その後、教育用言語として1980年代頃から広く普及した。1995年に登場するDelphiもPascalの血を引く言語である | |
| 1972年 | C | デニス・リッチー | プログラム開発の中心的な言語である | |
| 1979年 | Ada | アメリカ国防総省 | ジェネリックプログラミング(総称、汎化)、例外処理など先進的な考え方が初めに取り入れられた | |
| オブジェクト指向言語 | 1980年 | Smalltalk | - | オブジェクト指向を導入した黎明期の言語の1つであり、「オブジェクト指向」という言葉を最初に定義した言語でもある。後のオブジェクト指向型言語に多大な影響を与えた |
| 1983年 | C++ | - | C言語にオブジェクト指向を導入した、C言語と同様に開発の中心的な言語になった | |
| 1987年 | Perl | ラリー・ウォール | 主にCGIなどの用途で広く普及している | |
| 1991年 | VB | Microsoft社 | Windows専用のGUIアプリケーション開発言語 | |
| 1995年 | Delphi | ボーランド社 | Pascalの血をひくWindows専用のGUIアプリケーション開発言語 | |
| インタプリタ言語・仮想マシン | 1995年 | Java | サン・マイクロシステムズ社 | 本格的なオブジェクト指向言語の1つ。構文はC言語とかなり類似しているが、内容はまったく新世代の言語である、JavaVMという仮想マシン環境で動作 |
| 1995年 | Ruby | まつもとゆきひろ | Perlのように使えるスクリプト言語を、純粋なオブジェクト指向言語として設計 | |
| 1995年 | PHP | ラスマス・ラードフ | Webサーバ側スクリプト言語として現在までも広く使われている | |
| 1997年 | JavaScript | - | 標準仕様としてECMAScriptが標準化された | |
| 2002年 | C# | Microsoft社 | CLRという仮想マシン環境で動くオブジェクト指向言語。Javaの影響を強く受けており、C++とJavaの中間的な特徴をもつ | |
| 2009年 | Go | Google社 | 並列コンピューティングに配慮したコンパイラ言語。依存性の注入を言語仕様にとりこみ、例外処理やクラスの継承、アサーション、オーバーロードといった機能を排除している | |
| 2011 | Dart | Google社 | Webブラウザ組込みのスクリプト言語であるJavaScriptの代替となることを目的に作られた。 2014年ECMA-408と言う標準規格に登録 | |
| 2014 | Swift | Apple社 | Apple社のiOSおよびOS Xのためのプログラミング言語。従来から用いられていたObjective-CやObjective-C++、C言語と共存することが意図されている |
プログラミング言語とは、コンピュータに対する一連の動作の指示を記述するための人工言語のことです。プログラミング言語で記述されたこの一連の指示はプログラムと呼ばれ、それを記述することはプログラミングと呼ばれます。
コンピュータは、機械語と呼ばれる中央処理装置が直接解釈できる命令を実行することによって動作するものですが、人間にとって機械語を扱うことは非常に難しいため、機械語の代わりにプログラミング言語を用いることによって、より人間にとって扱いやすい表現でコンピュータに指示を与えることができるようになります。
プログラミング言語は様々な視点から分類することができます。
実行形態による分類
プログラムがどのように実行されるかという観点(実行形態)から、プログラミング言語を以下のように分類することができます。
- インタプリタ言語
- コンパイル言語
インタプリタ言語
インタプリタ言語はプログラムの実行時にプログラムのソースコードを1行ずつ逐一翻訳しながら進めていきます。例としては、以下の言語があげられます。
- Basic
- Javascript
- Perl
- Phyton
- Ruby
コンパイル言語
インタプリタ言語とは逆に、実行する前にすべてのソースコードを機械語に翻訳してしまい実行ファイルと呼ばれる形式に変換します。例としては、以下の言語があげられます。
- Cobol
- Fortran
- C++
- Pascal
- Java
- C#
- VB.net
判断基準について
JavaやC#、VB.netなどの.net系言語はプログラムが機械語にコンパイルされないが、JAVA仮想マシンの上に動作するバイト・コードや、.net frameworkランタイムの上に実行するILなどの中間コードを予め変換しておく必要があり、実行環境にはソースコードが配布されないため、コンパイル言語に分類することとします。
一方、Javascriptなどのスクリプト言語は、パフォーマンス最適化を求めるため、殆どのインタプリタが内部的にも中間コードに変換しておいてから実行することになりますが、ソースコードが稼動環境に配布しないといけないことと、中間コードがjava バイトコードのように仕様を標準化されておらず、各インタプリタの内部実装に依存することから、コンパイル言語に分類されません。
パラダイムによる分類
プログラムをどのように構成するかという観点(パラダイム)から、プログラミング言語を以下のように分類することができます。
- 手続き型言語
- オブジェクト指向言語
- 手続き+オブジェクト指向の言語
- 関数型言語
手続き型言語
手続き型プログラミングは、プログラムをデータ構造とルーチンの集合に分割し、「手続き呼び出し」の概念に基づきプログラミングを行います。「手続き」は実行すべき一連の計算ステップを持つもの、プロシージャ、ルーチン、サブルーチン、メソッド、関数(数学の関数とは異なるが、関数型言語における関数とほぼ同義)など様々な呼称があります。手続きはプログラム実行中の任意の時点で呼び出すことができ、他の手続きからの呼び出しも、自分自身からの呼び出し(再帰呼び出し)も含まれます。 例としては、下以の言語があげられます。
- basic
- C
- pascal
オブジェクト指向言語
オブジェクト指向プログラミングは、プログラムをオブジェクト(クラス)に分割し、オブジェクト間の「メソッド呼び出し」の概念に基づきプログラミングを行います。例としては、以下の言語があげられます。
- Java
- C#
- Javascript…
手続き+オブジェクト指向の言語
手続きプログラミングとオブジェクト指向プログラミングと両方をサポートしている言語です。例としては、以下の言語があげられます。
- c++
- Delphi(Object Pascal)
- VB
関数型言語
関数型言語とはすべての計算や処理などを関数の定義の組み合わせとして記述していくタイプのプログラミング言語です。主に科学計算や人工知能の領域に利用されており、業務アプリケーション開発に使われることはほとんどありません。 例としては、以下の言語があげられます。
- LISP
- F#
構文による分類
プログラムの構文という観点から、プログラミング言語を以下のように分類することができます。
- COBOL構文式
- ALGOL構文式
COBOL構文式
下記のように英語の文章のように記述できるのが特徴です。
| 代入文 | move value to variable. |
| 算術式 | add value1 to value2 giving variable
s ubtract value2 from value1 giving variable multiply value1 by value2 giving variable divide value1 by value2 giving variable |
| サブルーチンの呼び出し | call subroutine using para1 param2 returning result |
ALGOL構文式
BNF記号を利用します。
| 代入文 | variable=value. |
| 算術式 | variable = value1 + value2
variable = value1 - value2 variable = value1 * value2 variable = value1/ value2 |
| サブルーチンの呼び出し | result = subroutine(para1,para2); |
※COBOL等の言語の一部は新しいバージョンから+,-,*,/,=を含む構文もサポートされるようになりました。
用途による分類
用途という観点から、プログラミング言語を以下のように分類することもできますが、判断の基準は難しいところがあります。
- 汎用化言語
- ドメイン特化型言語
- Add-on言語
汎用化言語
より汎用的に使われることを目的として設計された言語のことです。例としては、以下のの言語があげられます。
- C
- C++
- Java
ドメイン特化型言語
特定の分野で使われることに目的を特化した言語のことです。例としては、以下のの言語があげられます。
- Fortran
科学技術計算用 - Cobol
事務処理用 - Php
WEBサイト作成
Add-on言語
特定のソフトウェアやプラットフォームの機能をカスタマイズや拡張するためのAdd-onを開発するための言語のことです。例としては、以下の言語があげられます。
- PL-SQL
Oracle DBMS - Transact-SQL
Sybase/SQLServer DBMS - ABAP
SAP ERP
SAP Business Suiteとは、SAP ERPをはじめとするSAP社の業務アプリケーションのスイート製品です。
SAP Business Suiteは、NetWeaverというSAPのテクノロジプラットフォームに基づいています。
構成
SAP Business Suiteは、以下のアプリケーション製品から構成されます。

- ERP(Enterprise Resource Planning)
- CRM(Customer Relationship Management)
- SCM(Supply Chain Management)
- PLM(Product Lifecycle Management)
- SRM(Supplier Relationship Management)
世代
SAP Business Suiteソリューションは、公式的にR/1、R/2、R/3、S/4の4世代に分けられるようになっています。
ここの「R」はリアルタイム、「S」はシンプルを意味しているそうです。
- R/1
1973年 メインフレームで動作する会計システム - R/2
1979年 R/1の進化版 - R/3
1992年 様々なプラットフォームで動作するクライアント・サーバ型の分散アプリケーションシステム - S/4
2015年 同社のインメモリデータベースHANAのみで動作する
Javaクラスファイルの構造は以下の構造体定義で示すことができます。
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
マジックナンバー
ClassFile構造体の先頭はマジックナンバーです.その値は16進でCAFEBABE と決まっています.先頭がCAFE BABEでないファイルはベリファイをパスしません。
バージョン
次の項目はこのクラスファイルを作成したバイトコード・コンパイラのバージョンです.バージョン番号がJavaVMのサポートしていないものだった場合は,それを実行することは許されていません.
コンスタントプール
コンスタントプールは定数やクラス名などを保持するためのものです.
コンスタントプールは可変長の要素を持つ,0~ConstantPoolCount-1までの一種の配列ですが,クラスファイルには0番目の要素は含まれていません.0 番のエントリはJavaVM内部用に予約されており,クラスファイルで使用することはできません.同時に0番は無効なインデックスであり,これを使用するクラスファイルはベリファイをパスしません.
コンスタントプールは配列として表現されてはいますが,要素が可変長であるため,添字から各エントリへ単純にアクセスすることはできません.
アクセスフラグ
このクラスの修飾子に対応するフラグです.access_flagsの各ビットが public,final,interface,abstractの各修飾子に対応しています.finalと abstract,finalとinterfaceのように,同時にセットすることが許されていないフラグもあり,もしそれらが同時にセットされているとベリファイをパスしません.
通常の修飾子とは異なるsuperというフラグもありますが,これは古いコンパイラとの互換性を保つためのものです.新しいコンパイラでは常にセットされていなければなりません.
現在のバージョンで使われていないビットもありますが,それらは将来に備えて予約されており,現在は常に0にしなければなりません.これはフィールド情報やメソッド情報にあるアクセスフラグでも同様です.
thisクラス
this_classはこのクラス自身を表しています.これはコンスタントプールへのインデックスになっており,コンスタントプール中の該当するエントリはこのクラスへの参照を表すCONSTANT_Class_infoになっています.
スーパークラス
super_classは直接のスーパークラスを表しています.直接のスーパークラスを持たないクラス(即ちjava.lang.Object)やインターフェースの場合は,この数値は0になります.それ以外の場合はthis_classと同様です.
スーパーインターフェース
interfaces[]は直接のスーパーインターフェースを表します.スーパークラスとは異なり,直接のスーパーインターフェースは複数持つ可能性があるので配列になっています.直接のスーパーインターフェースを持たない場合は interface_countが0になり,配列そのものがなくなります.それ以外は this_classやsuper_classと同様です.
図4の例では,this_classが2,super_classが1になっています.これより順に辿ると,このクラスの名前はGalaxyで,そのスーパークラスの名前は Sovereignであることが分かります.
フィールド情報
fields[]はfield_info構造体の配列で,このクラスで定義しているフィールドに関する情報を保持しています.
access_flagsの各ビットは,このフィールドの修飾子に対応しています. publicとprivate,finalとvolatileなどを同時にセットするとベリファイをパスしません.また,このクラスファイルがインターフェースを表していた場合, finalとstaticがセットされていないとベリファイをパスしません.
name_indexで指定されるCONSTANT_Utf8_infoはフィールド名として有効な文字の並びを保持していなくてはなりません.そうでなければベリファイをパスしません.descriptor_indexについても同様です.
コンスタントプール回りの例が図4にあります.もう見れば分かると思いますが,fields[0]がint型のNcc,fields[1]がint型のMiranda,fields[2]が iveLongAndProsper型のYouWillBeAssimilatedというフィールドを,それぞれ表しています.
メソッド情報
methods[]はmethod_info構造体の配列になっており,このクラスで定義されているメソッドに関する情報を保持しています.method_info 構造体は形式だけならばfield_info構造体と同じですが,ディスクリプタやアクセスフラグの詳細などが異なっています.
access_flagsの各ビットは,このメソッドの修飾子に対応しています. publicとprotected,abstractとfinalなど,同時に使用できないフラグもあります.それらが同時にセットされていた場合は,ベリファイをパスしません.
属性
属性とは,今まで紹介された以外の様々な情報を保持するものです. ClassFile構造体の他,field_info構造体,method_info構造体,そして属性であるCode_attribute構造体の中で使われます.属性には仕様書で定義されている定義済み属性と,新たにユーザーが定義する属性とに分けられます.
属性の基本フォーマットとなるattribute_info構造体を図8に示します.全ての属性はこのフォーマットに従わなければなりません.逆に言えばこのフォーマットに従っており,且つ定義済み属性で予約されていない有効な名前を持つ属性ならば,新たに定義することはユーザーの自由です.
当然のことながら,ユーザーによって新たに定義された属性の中には JavaVMが認識できないものも出てきます.このため,認識できない属性を単純に読み飛ばすことはJavaVMに必須の機能になっています.
定義済み属性
JavaVM仕様書で定義されている定義済み属性の一覧を下記の表に示します.このうち,JavaVMが必ず認識しなければならない属性はCode属性,ConstantValue 属性,Exceptions属性,InnerClasses属性,Synthetic 属性の5つです.それ以外の属性については必ずしも認識する必要はありません.(もちろん認識した方がより良いのですが.)
表3:定義済み属性一覧
| 属性 | 内容 | 使用される場所 |
|---|---|---|
| ConstantValue属性 | staticの定数フィールドの値 | field_info |
| Code属性 | バイトコードなど,メソッドの実装に関する情報 | method_info |
| Exceptions属性 | メソッドがスローするチェック例外 | method_info |
| InnerClasses属性 | 内部クラスに関する情報 | ClassFile |
| Synthetic属性 | このメンバーがソースコードに現れないものであることを示す | ClassFile field_info method_info |
| SourceFile属性 | このクラスを定義しているソースファイル名 | ClassFile |
| LineNumberTable属性 | code配列への添字(即ちバイトコード)と,その元となるソースファイル中の対応する行番号 | Code_attribute |
| LocalVariableTable属性 | 各メソッドのローカル変数に関する情報 | Code_attribute |
| Deprecated属性 | クラス,インターフェース,メソッド,フィールドが,既に新しいものと置き換えられたことを示す | ClassFile field_info method_info |
以下の表にて、カテゴリー別にdojoライブラリのモジュールをリストアップしてみました。
| カテゴリ | モジュール名 | 概要 |
|---|---|---|
| Dojo Kernel | dojo/_base/kernel | versionの表示や、deprecatedな関数を実行したときに警告を出すと言ったライブラリのごく基本的な機能を提供。 |
| Dojo Configuration | dojo/_base/config | Dojoの設定に関連。 |
| Module Loading | dojo/_base/loader | 旧ローダー及びAMDローダー。 |
| dojo/require | ||
| Loader Plugins | dojo/domReady | AMDローダーのプラグイン |
| dojo/i18n | ||
| dojo/has | ||
| dojo/node | ||
| dojo/text | ||
| Feature Detection | dojo/has | クロスプラットフォームの機能検出と管理 |
| dojo/sniff | ||
| dojo/uacss | ||
| dojo/_base/sniff | ||
| Language | dojo/_base/lang | 基礎的な言語の拡張パッケージ |
| Classes | dojo/_base/declare | 型システム |
| Deferreds and Promises | dojo/promise | 非同期処理関連 |
| dojo/Deferred | ||
| dojo/when | ||
| dojo/_base/Deferred | ||
| dojo/DeferredList | ||
| Events, Connections | dojo/on | イベントハンドリング関連。dojo/_base/connectとdojo/_base/eventは実質的にdeprecated |
| dojo/_base/connect | ||
| dojo/_base/event | ||
| dojo/Evented | ||
| dojo/behavior | ||
| Aspect Oriented Programming | dojo/aspect | AOP関連 |
| Requests | dojo/request | Ajaxのコアとなるリクエストのハンドリング関連 |
| dojo/_base/xhr | ||
| dojo/io/iframe | ||
| dojo/io/script | ||
| Properties | dojo/Stateful | オブジェクトクラスのプロパティの管理。 |
| Topics/Publish/Subscribe | dojo/topic | publish/subscribeパターン |
| Data and Stores | dojo/store | クライアントサイドのデータハンドリング |
| dojo/data | ||
| Router | dojo/router | Hashベースのコールバックの仕組み。dojo/hashを使っている。 |
| Parser | dojo/parser | data-dojo-typeが指定されたノードをDijitのウィジェットに変換する |
| DOM and HTML | dojo/dom | DOMとHTMLを操作する |
| dojo/dom | ||
| dojo/dom-attr | ||
| dojo/dom-class | ||
| dojo/dom-construct | ||
| dojo/dom-form | ||
| dojo/dom-geometry | ||
| dojo/dom-prop | ||
| dojo/dom-style | ||
| dojo/dom-html | ||
| dojo/_base/html | ||
| Query, NodeList and Selectors | dojo/query | DOMクエリとその結果に対する操作を拡張。 |
| dojo/NodeList | ||
| dojo/NodeList-data | ||
| dojo/NodeList-dom | ||
| dojo/NodeList-fx | ||
| dojo/NodeList-html | ||
| dojo/NodeList-traverse | ||
| dojo/selector | ||
| dojo/_base/query | ||
| dojo/_base/NodeList | ||
| DOM Effects | dojo/_base/fx | DOMのアニメーション関連 |
| dojo/fx | ||
| Browser Window | dojo/window | クロスブラウザな表示領域関連の参照。 |
| dojo/_base/window | ||
| Document Lifecycle | dojo/ready | Documentのライフサイクル関連 |
| dojo/domReady | ||
| dojo/_base/unload | ||
| Browser History | dojo/back | ブラウザのヒストリの管理 |
| dojo/hash | ||
| Cookies | dojo/cookie | Cookieの管理 |
| Mouse, Touch and Keys | dojo/mouse | ユーザインプットの正規化と管理 |
| dojo/touch | ||
| dojo/keys | ||
| Drag and Drop | dojo/dnd | Drag and Drop関連 |
| Testing | dojo/robot | ユーザ入力のエミュレーション |
| dojo/robotx | ||
| JS基本オブジェクト拡張 | dojo/_base/array | 配列関連の拡張 |
| dojo/string | 文字列処理の拡張 | |
| dojo/json | JSON関連 | |
| dojo/_base/json | ||
| dojo/_base/Color | 色関係のクラスと関数 | |
| dojo/colors | ||
| dojo/date | Dateの拡張 | |
| URL and Query Strings | dojo/_base/url | URLとURLクエリストリングの管理 |
| dojo/io-query | ||
| Internationalization | dojo/i18n | アプリケーションの国際化関連モジュール |
| dojo/nls | ||
| dojo/cldr | ||
| dojo/number | ||
| dojo/currency | ||
iframe要素は、別の文書を埋め込むインライン・フレームを作る際に使用します。
HTML5では、次の属性が廃止されました。
- frameborder属性
- marginheight属性
- marginwidth属性
- scrolling属性
- longdesc属性
また、次の属性が新しく追加されました。
- srcdoc属性
- sandbox属性
- seamless属性
srcdoc属性
srcdoc属性はiframe要素で埋め込むHTML文書の内容を指定します。つまり、表示したいHTMLを属性値として直接入力します。
srcdoc 属性値に入る 「“」 及び 「&」 は実体参照文字(それぞれ 「"」「&」)でエスケープする必要があります。
sandbox属性
sandbox属性を指定すれば、そのインラインフレーム内のコンテンツは次のような制限がかけられます。
- 同じドメイン内の文書であったとしても別ドメインの文書として扱われます
- ほかのウィンドウやフレームを操作できなくなります、子孫フレームは操作可能
- 最上位のウィンドウを操作できなくなります
- フォームの送信を無効化します
- スクリプトの実行を無効化します
一部の制限は、以下のキーワードの指定によって解除することが可能です。
- allow-same-origin
親文書と同じドメインを持つものとする - allow-top-navigation
最上位のウィンドウの操作を許可する - allow-scripts
スクリプトの実行を許可する
seamless属性
seamless属性が指定されると、そのiframe要素で読み込まれたコンテンツは、親ドキュメントの一部としてレンダリングされるようになります。
概説
クロージャとは、「関数の外側で定義された変数を持つ関数の実行時オブジェクト」です。
JavaScriptでは、関数もオブジェクトであり、生成から廃棄されるまでのライフルサイクルを持ちます。関数が外側の関数で定義されたローカル変数を参照していれば、関数オブジェクト生成時の実行環境も関数オブジェクトの属性の一部(クロージャスコープ属性)として維持し続けられます。
サンプル
下記のコードを例として説明します 。
var x = 1;
function Counter() {
var n = 0;
return function () {
n = n + x;
return n;
};
}
関数Counter()は、内部でローカル変数nを定義して、それを参照するクロージャを返します。
実行1
var a = Counter();
console.log("a()=" + a());
console.log("a()=" + a());
console.log("a()=" + a());
console.log("a()=" + a());
上記コードの実行結果は次の通りになります。
a()=1 a()=2 a()=3 a()=4
変数nの値が保持されていることは分かります。
Counter()実行後の環境の状態
┌────────┐
グローバル環境 ┌───────┐
x => 1 ←─ Counterの環境
a => function n => 0 ←─ クロージャa
└────────┘ └───────┘
実行2
var a = Counter();
var b = Counter();
console.log("a()=" + a());
console.log("a()=" + a());
console.log("b()=" + b());
console.log("a()=" + a());
console.log("b()=" + b());
実行結果は次の通りです 。
a()=1 a()=2 b()=1 a()=3 b()=2
関数Counter()が実行されるごとに異なる環境が生成されることはわかります。
Counter()2回実行後の環境の状態
┌────────┐ ┌──────────┐
グローバル環境 ←─ 1回目のCounterの環境
x => 1 n => 0 ←─ クロージャa
a => function └──────────┘
b => function ┌──────────┐
└────────┘ ←─ 2回目のCounterの環境
n => 0 ←─ クロージャb
└──────────┘
構文構造を利用
例1:
var o = {
a: 1
}; 上記のoは Object.prototype をプロトタイプとして生成され、 o.hasOwnProperty('a') がtrueを戻します。
例2:
var a = ["yo", "whadup", "?"];
上記のaは Array.prototype をプロトタイプとして生成され、三つの要素を持ちます。
コンストラクタ関数を利用
JavaScriptに於ける「コンストラクタ」は、関数を new 演算子を使って呼び出す事で実現可能です。
下記のコードを例とします。
function Graph() {
this.vertexes = [];
this.edges = [];
}
Graph.prototype = {
addVertex: function(v){
this.vertexes.push(v);
}
};
var g = new Graph();
上記のコードで生成されるg は「vertexes」と「edges」の自身のプロパティを持つオブジェクトであり、 g.[[Prototype]] はインスタンス化する時点の Graph.prototype の値になります。
Object.Create メソッドを利用
ECMAScript 5 は Object.create という新しいメソッドを紹介しています。このメソッドを呼び出すと、新しいオブジェクトが生成されます。
関数の最初の引数が、このオブジェクトのプロトタイプになります。
var o1 = { // o1 ---> Object.prototype ---> null
a: 1
};
var o2 = Object.create(o1); // o2 ---> o1 ---> Object.prototype ---> null
console.log(o2.a); // 1 (継承された)
var o3 = Object.create(o2); // o3 ---> o2 ---> o1 ---> Object.prototype ---> null
var o4 = Object.create(null); // o4 ---> null
console.log(o4.hasOwnProperty); // undefined、なぜなら o4 は Object.prototype から継承していないからです。